
Contents
Was ist eine Suchmaschine?
Pro Sekunde bearbeitet die marktführende Suchmaschine Google rund 50.000 Suchanfragen. Das sind 3,5 Milliarden pro Tag. Die schnelle Suche nach Informationen für Beruf, Ausbildung und Privatleben ist kaum mehr wegzudenken. Damit scheinen auch Zeiten spekulativer Stammtischdiskussionen vorbei. Denn die ehemaligen Trümpfe der Lautstärke, des Charismas und der meisten Freunden am Tisch werden von einigen wenigen Bewegungen auf dem Smartphone und der (vermeintlich) korrekten Info gnadenlos ausgestochen.
Aber wie funktioniert eine Suchmaschine eigentlich? Grundlegend arbeitet eine Suchmaschine in drei Schritten:
- Schritt 1: Auffinden der Daten
- Schritt 2: Aufbereiten
- Schritt 3: Ermittlung der Relevanz bei Suchanfragen.
Schritt 1: Auffinden der Daten durch Suchmaschinen
Für das Auffinden der Daten ist der sogenannte „Crawler“ oder „Spider“ zuständig. Der Crawler ist ein Programm, das den HTML Code von Internetseiten ausliest und durch Links gefundene, neue URLs in einer Variablen abspeichert. Startpunkt sind dabei schon bekannte „Seed“ URLs.
Die Variable mit neu gefundenen URLs wird in einer Schleife nacheinander ausgelesen, um neue URLs aufzufinden und wieder abzuspeichern. Dabei gilt: Die ältesten URLs werden zuerst ausgelesen, die neu gefundenen werden an das Ende der Schlange gestellt. Diese Technik heißt Breadth-First-Search (BFS).

Es sind immer mehrere Crawler unterwegs
Weil das Internet mit einer vermuteten Anzahl von einer Billion Seiten und 1,4 Millionen neuen Unterseiten pro Sekunde sehr groß und ständig in Bewegung ist, würde ein einzelner Crawler nicht ausreichen. Daher werden auch wichtige Knotenpunkte ständig als neue Seed URLs ausgemacht und der Prozess an verschiedenen Stellen im Web neu und parallel gestartet. Da crawling nicht gesetzlich geregelt ist, sind also mehrere Webspider von verschiedensten Diensten unterwegs. Je häufiger eine Seite verlinkt ist, desto häufiger wird sie gecrawlt und neue Seiten bzw. Veränderungen schneller indexiert. Das ist ein Grund für Linkbuilding von SEO Agenturen.
Schritt 2: Aufbereitung von Daten durch Suchmaschinen
Die URLs werden in einem Repository gespeichert und mit einem Zeitstempel versehen. Dort werden sie von dem Indexer oder Parser aufgegriffen, der die Seite vereinfacht und relevante Suchbegriffe herausfiltert. Grundlage der Einschätzung, ob es sich tatsächlich um relevante Wörter handelt, ist ein riesiges Schlüsselwortset. Es handelt sich sogar vielmehr um eine Art Lexikon, eigentlich eine ganze Reihe von Lexika, die Namen und Orte speichern, Rechtschreibung abgleichen, oder auch semantische Verbindungen zwischen Worten erkennen.
Wordstemming: So bauen Suchmaschinen ihre Datenbanken auf
Das System basiert auf „Wordstemming“. Deklinationen (geht, ging, gingen, gehen etc.) werden auf den Grundbegriff zurückgeführt (gehen), das Gleiche passiert mit Nomen des gleichen Wortstamms (Gang, das Gehen). Die Ursprüngliche Verwendung des Wortes auf einer eingelesenen Webseite wird aber ebenfalls gespeichert, quasi in einem Unterordner von „gehen“. Stoppwörter oder Füllwörter (der, die, das, man, diese, welche, sind etc.) bekommen keinen eigenen übergeordneten Ordner. So kann die Suchmaschine sowohl die übergeordnete Semantik als auch den genauen gefundenen Wortlaut erkennen.
Die einzelnen Begriffe und deren semantischer Zusammenhang werden aber nicht in Klartext gespeichert. Vielmehr hat jeder einzelne „Ordner“ eine zugeordnete Codierung. Sagen wir in einem extrem vereinfachten Beispiel, das Grundwort „gehen“ hat den Buchstaben „G“ als zugeordnete Codierung, „Canossa“ „C“. Die untergeordneten Begriffe bekommen jeweils einen eigenen Code zugeordnet, für die Überkategorie „gehen“ beispielsweise gehen (0) ging (1) Gang (2) Eingang (3) übergehen (4) usw.:
| Begriff | Gehen (G) |
Canossa (C) |
Nach (-) |
| Codierungen des Wortstamms | Gehen (0) | Canossa (0) | Stoppwort (-) |
| Ging (1) | Canosa (0) (erkannter Rechtschreibfehler) |
möglicher Rechtschreibfehler von „Nacht“ (N0) | |
| Gang (2) |
In diesem einfachen Beispiel kann der Wortfolge dann der Code „A2C0“ zugeordnet werden. Der Ausdruck „Gang nach Canossa“ ist zusätzlich eventuell als Sprichwortteil oder Bewegung erkannt worden. Es gibt darüber hinaus noch Codierungen für Eigenschaften, wie Wissenschaft, Technik usw.:
| Begriff | Gehen | Canossa | Nach |
| Semantische Codierungen | Codierung als Bewegung (b) | Codierung als Name (n) | Codierung als Bewegung (b) |
| Codierung als Sprichwortteil (s) | Codierung als Zeitangabe (z) |
Für unser Beispiel entsteht so der Code „A2xbbzC0ns“. Die einzelnen zuvor gespeicherten URLs werden in IPs umgewandelt und jede bekommt jeweils eine Reihe solcher Codes zugewiesen.
Achtung: Das gewählte Beispiel ist extrem verkürzt und wird den modernen, hochkomplexen Algorithmen nicht gerecht. Von der Formulierung eines Textes kann der Algorithmus sogar Rückschlüsse auf den Bildungsgrad des Autors schließen – selbst wenn Rechtschreibfehler ignoriert werden.
Schritt 3: Erkennung der Relevanz von Begriffen und Seiten
Die Frage wie eine Suchmaschine die Relevanz von Begriffen bestimmt, ist oft ein Betriebsgeheimnis und Gegenstand von Spekulation in der Suchmaschinenoptimierung. Einige Faktoren können aber als wahrscheinlich gelten:
- Vorkommen im <title> Tag der Seite
- Vorkommen in Überschriften (<h1>, <h2>, …)
- Vorkommen im Fließtext
- Besondere Kennzeichnung im Fließtext (fett, kursiv)
- Vorkommen zu Beginn von Textabschnitten
- Vorkommen als Aufzählungspunkt einer Liste
- Vorkommen in anderen Dokumenten der Domain
- Vorkommen semantisch ähnlicher Begriffe
- …und weitere Faktoren.
Neben diesen Faktoren, die weitesten Sinn „onpage“ genannt werden, gibt es auch Faktoren außerhalb des Quellcodes, die wichtig sind (offpage). Hierzu zählt die Anzahl und Qualität von Seiten, die auf eine Internetseite verweisen, sogenannte „Backlinks“. Auch personenbezogene Einstellungen spielen eine Rolle: Sprache, Land, Land des Webservers, momentane Aktualität bestimmter Suchbegriffe, Art des Gerätes usw. bestimmen die Reihenfolge der Suchergebnisse.
Suchmaschinen sind teilweise schon künstlich intelligent
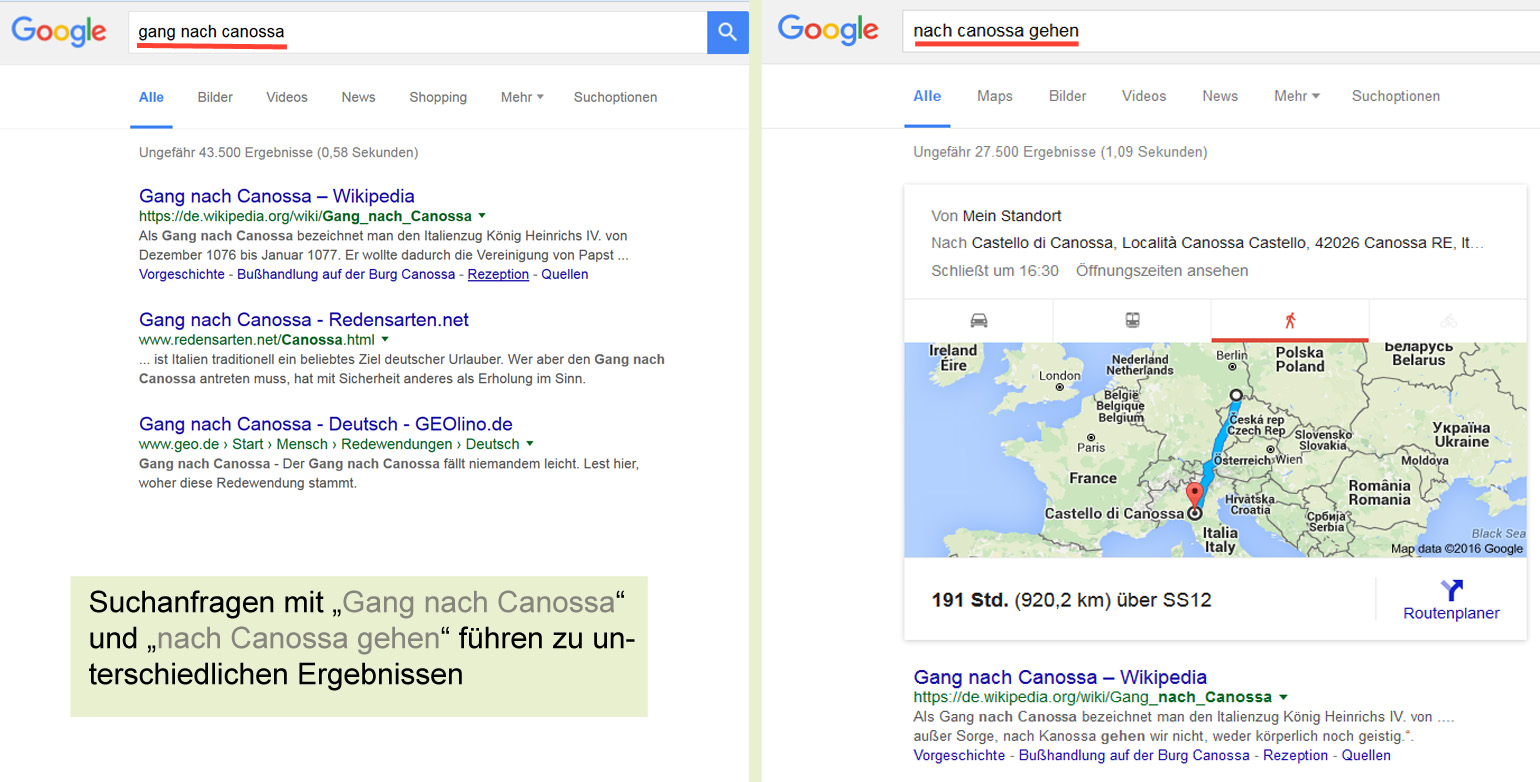
Wie sensibel z.B. Google die Suchanfragen behandelt, zeigt folgendes Beispiel: Bei der Suchanfrage „Gang nach Canossa“ werden die einschlägigen Seiten aufgeführt, die das Sprichwort erklären. Bei „nach Canossa gehen“ wittert die Suchmaschine bereits einen anderen Zusammenhang und spielt sicherheitshalber auch die Route auf Google Maps aus. Von Dresden nach Canossa sind es übrigens 920 Km und man benötigt 191 Stunden zu Fuß.
Suchmaschinen nutzen aber auch den Nutzer selbst, um die Relevanz von Seiten einzuschätzen. Gibt ein Nutzer beispielsweise ein Suchwort ein, geht auf eine Seite und verlässt sie sofort wieder, scheint diese Seite für die Suche nicht relevant zu sein. Bleibt er länger, ist anscheinend Relevanz gegeben.
Vermutet aber zum Beispiel Google einen Betrug, um die Relevanz der Seite zu verbessern, kann es zu einer Abstrafung kommen. Bei einer solchen Überoptimierung sollte man seine Fehler erkennen, ausbessern und warten. Oder man geht ihn, den Gang nach Canossa und bittet Google mit der Betonung der Einsicht um eine erneute Überprüfung (reconsideration request).
Nutzen Sie für Ihre SEO-Strategie das Know-how von clicks digital. Als renommierte SEO-Agentur in Deutschland beraten und unterstützen wir Sie gerne. Kontaktieren Sie uns und lassen Sie uns gemeinsam durchstarten!