
Das Wissen um die Bedeutung der Statuscodes und -klassen trägt für Webseitenbetreiber erheblich dazu bei, die aktuelle Situation der eigenen Seite zu erfassen und etwaige Fehler möglichst früh zu lokalisieren und einzugrenzen. Im Folgenden werden deshalb die verschiedenen Statusklassen sowie die wichtigsten Statuscodes 200, 301, 302 und 404 kurz vorgestellt.
Grundsätzlich werden Statuscodes als dreistellige Ziffern dargestellt. Die erste Zahl gibt dabei Aufschluss darüber, um welche der insgesamt sechs verschiedenen Statusklassen es sich handelt:
Contents
Die HTTP Statuscodes auf einen Blick
| Statusklasse | Bedeutung |
| 1xx | Die Bearbeitung der Anfrage dauert an |
| 2xx | Die gestellte Anfrage konnte erfolgreich bearbeitet werden |
| 3xx | Um die Anfrage auszuführen sind weitere Maßnahmen seitens des Clients erforderlich |
| 4xx | Die Anforderung enthält einen Fehler, der die Verarbeitung der Anfrage verhindert |
| 5xx | Bei der Verarbeitung der Anfrage ist intern (also auf dem Server) ein Fehler aufgetreten |
| 9xx | Der Fehler wird vom Netzwerk verursacht, der Client soll die Anfrage erneut senden |
Statuscode 200: Der Idealfall
Wenn bei einer Anfrage der Statuscode 200 zurückgegeben wird, bedeutet dies, dass die Anfrage vom Server erfolgreich bearbeitet und die erwartete Antwort ausgegeben wird. Einfacher ausgedrückt: die Seite ist ohne Probleme aufrufbar – ein gutes Zeichen für den User, den Webseitenbetreiber und den Webcrawler von Google, der von Zeit zu Zeit die eigene Seite untersucht.
Statuscode 301: Die dauerhafte Weiterleitung
Bei diesem Statuscode ist die angefragte Ressource dauerhaft auf eine andere Adresse verschoben. Die alte Adresse ist also nicht länger gültig, aber immer noch unter der im Location-Header-Feld angegebenen Adresse zu finden („Redirect“).
Prinzipiell ist es ratsam, die einmal vergebene URL-Struktur einer Webseite nicht weiter zu ändern. Dies ist aber unrealistisch – besonders bei dynamischen Webseiten wie Onlineshops, deren Inhalte im ständigen Wandel sind, führt früher oder später kein Weg an permanenten Weiterleitungen vorbei.
Auch bei einem Domainumzug sind 301-Weiterleitungen unvermeidlich. Wichtig ist es hierbei, alle Seiten 1:1 umzuleiten – also die alte Startseite zur neuen Startseite, die alte Kategorie A zur neuen Kategorie A und so weiter.
Des Weiteren sollten Weiterleitungsschleifen und lange Weiterleitungsketten unbedingt vermieden werden, da der Google-Bot nach der vierten bis fünften Weiterleitung aufhört zu crawlen. Ganz auf Weiterleitungen zu verzichten ist aus SEO-Sicht jedoch eine sehr schlechte Idee: 301-Weiterleitungen leiten nämlich auch zu großen Teilen den Linkjuice weiter. Der Begriff Linkjuice beschreibt dabei die Backlink-Verteilung innerhalb einer Webseite und die Stärke bzw. Reputation dieser Links. Mit jeder Verlinkung wird also immer Linkjuice von der Ausgangsseite auf die Zielseite geleitet.

Statuscode 302: Weiterleitung auf Zeit
Analog zur 301-Weiterleitung besagt dieser Statuscode, dass die Ressource temporär nicht unter der angefragten Adresse zu finden ist. Der Unterschied liegt hierbei in der Zeitangabe: Bei 302 Statuscodes bleibt die angefragte Adresse gültig, bei 301-Statuscodes nicht. Der Googlebot crawlt und indexiert also weiterhin die ursprüngliche Zielseite. Außerdem wird bei diesem HTTP-Statuscode der Linkjuice – im Gegensatz zu 301-Weiterleitungen – nicht vererbt.
Auf den Statuscode 302 sollten Seitenbetreiber also nur zurückgreifen, wenn eine temporäre Weiterleitung angebracht ist. Sinnvoll sind 302-Weiterleitungen bspw. für Seiten, die aufgrund des Warenkorbs, Login-Vorgängen und Produktvergleichen entstehen und deshalb von Google indexiert werden.
Statuscode 404: Achtung – Hier stimmt etwas nicht!
Der Statuscode 404 besagt, dass die angefragte Ressource nicht unter der angefragten Adresse zu finden ist, da sie nicht (oder nicht mehr) existiert. Die Gründe dafür können vielfältig sein: die internen Links wurden nach einem Domain-Umzug nicht angepasst, externe Links verweisen noch auf die alte Adresse („Tote Links“) oder es wurde schlichtweg eine falsche URL verlinkt bzw. im Browser aufgerufen. Welche Ursache auch immer zu Grunde liegt – 404-Fehlermeldungen sollten von Webseitenbetreibern ernst genommen und deren Anzahl so gering wie möglich gehalten werden.
Wie man 404-Fehler (die leider oftmals unvermeidbar sind) originell und userfreundlich gestalten kann, zeigt die Frauenseite Erdbeerlounge: Deren Fehlerseite ist angereichert mit einem speziell für die Fehlerseite gestaltetem Bild, einem Tipp zur Fehlerbehebung, einer Bitte um Mithilfe zur Fehlersuche, einem Verweis auf die eigene Facebook-Seite und weiterführenden Navigationselementen im Footerbereich.
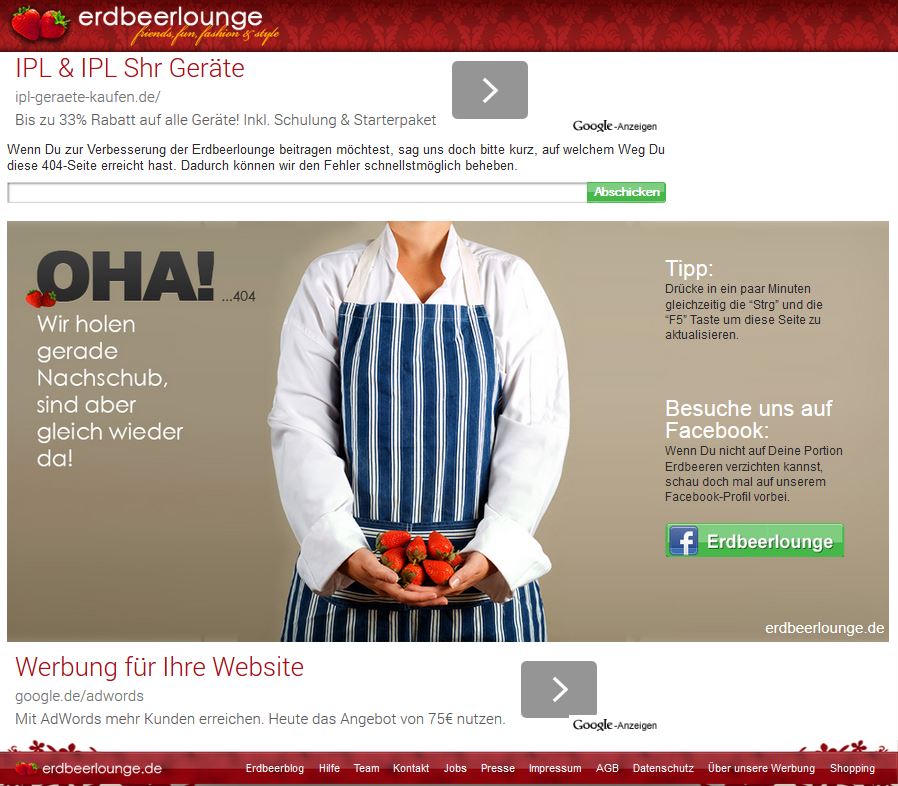
Dieses Beispiel zeigt auf, dass 404-Seiten für den User keine Sackgasse sein müssen. Durch geschickte Einbindung von relevanten Seitenelementen kann die Absprungrate nach einem Statuscode 404 erheblich gesenkt werden, solange sich der User von der Fehlerseite „abgeholt“ fühlt.
Fazit – Vertrauen ist gut, Kontrolle ist besser
Die vorgestellten Statuscodes sind die Bekanntesten – jeder Webseitenbetreiber sollte aber auch von den zahlreichen anderen Statuscodes und -klassen zumindest schon einmal gehört haben und sie einordnen können.
Jeder Seitenbetreiber sollte von Zeit zu Zeit seine eigene Webseite crawlen, um die Statuscodes aller URLs im Auge zu behalten. Ein empfehlenswertes Crawler-Tool hierfür ist Screaming Frog (weitere Informationen dazu hier). Alternativ eignen sich auch die Webmaster Tools von Google (bei „Status“ / „Crawling-Fehler“) prinzipiell gut dazu, 404-Fehler zu identifizieren.
Unser Fazit ist daher: Die HTTP Statuscodes der eigenen Webseite sollten unbedingt regelmäßig (und vor allem nach einem Domainumzug) kontrolliert werden, um bösen Überraschungen vorzubeugen!